The famous probabilist and statistician Persi Diaconis wrote an article not too long ago about the "Markov chain Monte Carlo (MCMC) Revolution." The paper describes how we are able to solve a diverse set of problems with MCMC. The first example he gives is a text decryption problem solved with a simple Metropolis Hastings sampler.
I was always stumped by those cryptograms in the newspaper and thought it would be pretty cool if I could crack them with statistics. So I decided to try it out on my own. The example Diaconis gives is fleshed out in more details by its original authors in its own article.
The decryption I will be attempting is called substitution cipher, where each letter of the alphabet corresponds to another letter (possibly the same one). This is the rule that you must follow for the cryptogram game too. There are 26! = 4e26 possible mappings of the letters of the alphabet to one another. This seems like a hopeless problem to solve, but I will show you that a relatively simple solution can be found as long as your reference text is large enough and the text you are trying to decipher is also large enough.
The strategy is to use a reference text to create transition probabilities from each letter to the next. This can be stored in a 26 by 26 matrix, where the ith row and jth column is the probability of the jth letter, given the ith letter preceded it. For example, the given the previous letter was a Q, U almost always follows it, so the Q-row and U-column would be close to probability of 1. Assuming these one step transition probabilities are what matter, the likelihood of any mapping is the product of the transition probabilities observed.
To create a transition matrix, I downloaded War and Peace from Project Gutenberg. I looped through each letter and kept track of the number of number of times each letter followed the previous. I also kept track of a 27th character, which was anything that was not a letter -- for example periods, commas, spaces, etc. This lets me know which letters are more likely to start a word or end a word. Consecutive entries of these special characters are not considered.
After I have these counts, I normalize by dividing by the row total. Before normalizing, I add 1 to each cell so that there are no probabilities of 0. This also corresponds to prior information of each transition being equally likely. I could have tried to give more informative prior information (like Q to U being likely), but it would have been difficult and probably inaccurate for the whole matrix.
Below is the code for creating the transition probability matrix. Note that I loop through each line and within each line I loop through each character.
Created by Pretty R at inside-R.org
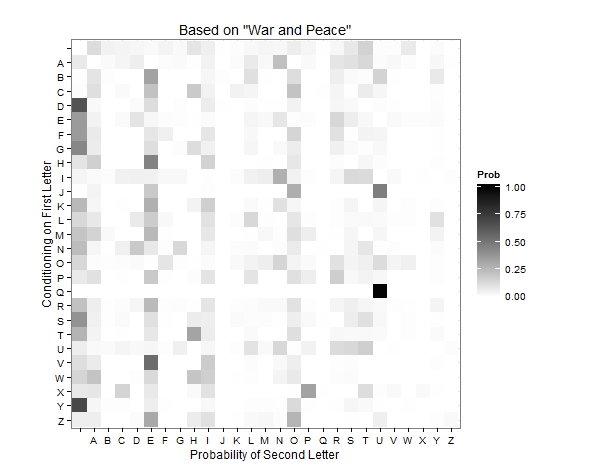
I like to visualize my data to make sure everything looks correct. Below is a plot of the transition matrix. The blank space corresponds to non-letter character. A lot of insights can be garnered from this plot. The Q-U relationship pops out. T is the most likely letter to start a word. E is a popular letter to follow many others. Y is likely to end a word.
The desired solution will be the one that gives the highest likelihood. This is an NP-hard problem so the only way to find the solution is to try all 26! combinations of mappings, which is infeasible, and report the one with the highest likelihood.
With the MCMC approach you start with a random mapping of letters. Next you propose a new mapping by randomly switching 2 of the characters in the mapping. So if A mapped to G and L mapped to Z and you switched those two, A would map to Z and L would map to G. With this new mapping, you measure the likelihood and divide it by the likelihood of the previous mapping. If this ratio is greater than 1, then move to this new mapping. If the ratio is less than 1, meaning the new mapping is less likely, then move to this new mapping with a probability equal to the ratio. (Practically, this is done by drawing a random uniform number between 0 and 1 and moving to the proposed mapping if the uniform number is less than the ratio.) Repeat this process until you think you have found a solution.
To do this, I first wrote a few functions. One to decode the coded text based on the mapping. The other was to calculate the log likelihood of the decoded text.
Created by Pretty R at inside-R.org
To show how this works, I will use the same Shakespeare text that is used in the MCMC Revolution paper. I let it run until it tries out 2000 different mappings (not the same as 2000 iterations, because rejected proposals are not counted). Along the way I am keeping track of the most likely mapping visited, and that will be the final estimate. It should be noted that I am only considering the mapping of letters and it is assumed that the special characters are known. For example spaces and periods are assumed to be the same.
Created by Pretty R at inside-R.org
The output of this example is below. You can see that it comes close but it doesn't quite find the correct mapping. I attribute this to the fact that the text I was trying to decode only had 203 characters. In the paper mentioned above, they decoded the whole play. They further say that their methods work just as well if you randomly sample a text snippet 2000 characters long. Obviously my example had well less than this. This is also a problem in trying to solve a cryptogram because those are even smaller than the Hamlet example I used. So unfortunately this simple method cannot be used for that. (Note that I ran the MCMC chain a several times, using different random starting points, until it came reasonably close to the solution. This is something that the authors also suggested doing.)
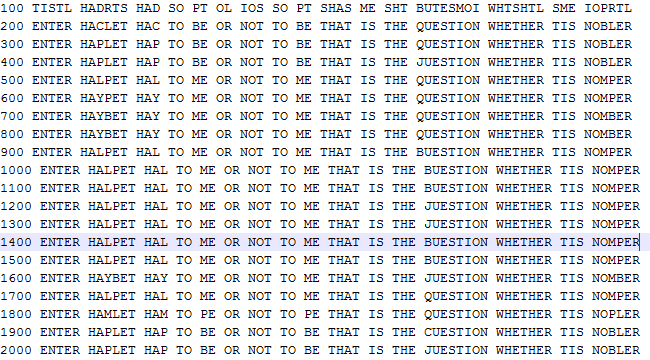
I want to also note that I originally used Alice and Wonderland as the reference text. It had more trouble decoding since this book is much smaller than War and Peace, and therefore the transition probabilities were not as good.
The MCMC method is a greedy approach in that you are moving to any mapping that increases the likelihood. Greedy methods are not optimal in general because they can get stuck at local modes, especially in high dimensional problems. MCMC avoids this be moving to less likely mappings with some probability, which ensures that it will find the correct solution with enough time.
I was always stumped by those cryptograms in the newspaper and thought it would be pretty cool if I could crack them with statistics. So I decided to try it out on my own. The example Diaconis gives is fleshed out in more details by its original authors in its own article.
The decryption I will be attempting is called substitution cipher, where each letter of the alphabet corresponds to another letter (possibly the same one). This is the rule that you must follow for the cryptogram game too. There are 26! = 4e26 possible mappings of the letters of the alphabet to one another. This seems like a hopeless problem to solve, but I will show you that a relatively simple solution can be found as long as your reference text is large enough and the text you are trying to decipher is also large enough.
The strategy is to use a reference text to create transition probabilities from each letter to the next. This can be stored in a 26 by 26 matrix, where the ith row and jth column is the probability of the jth letter, given the ith letter preceded it. For example, the given the previous letter was a Q, U almost always follows it, so the Q-row and U-column would be close to probability of 1. Assuming these one step transition probabilities are what matter, the likelihood of any mapping is the product of the transition probabilities observed.
To create a transition matrix, I downloaded War and Peace from Project Gutenberg. I looped through each letter and kept track of the number of number of times each letter followed the previous. I also kept track of a 27th character, which was anything that was not a letter -- for example periods, commas, spaces, etc. This lets me know which letters are more likely to start a word or end a word. Consecutive entries of these special characters are not considered.
After I have these counts, I normalize by dividing by the row total. Before normalizing, I add 1 to each cell so that there are no probabilities of 0. This also corresponds to prior information of each transition being equally likely. I could have tried to give more informative prior information (like Q to U being likely), but it would have been difficult and probably inaccurate for the whole matrix.
Below is the code for creating the transition probability matrix. Note that I loop through each line and within each line I loop through each character.
reference=readLines("warandpeace.txt")
reference=toupper(reference)
trans.mat=matrix(0,27,27)
rownames(trans.mat)=colnames(trans.mat)=c(toupper(letters),"")
lastletter=""
for (ln in 1:length(reference)) {
if (ln %% 1000 ==0) {cat("Line",ln,"\n")}
for (pos in 1:nchar(reference[ln])) {
curletter=substring(reference[ln],pos,pos)
if (curletter %in% toupper(letters)) {
trans.mat[rownames(trans.mat)==lastletter,
colnames(trans.mat)==curletter]=
trans.mat[rownames(trans.mat)==lastletter,
colnames(trans.mat)==curletter]+1
lastletter=curletter
} else {
if (lastletter!="") {
trans.mat[rownames(trans.mat)==lastletter,27]=
trans.mat[rownames(trans.mat)==lastletter,27]+1
lastletter=""
}
}
}
curletter=""
if (lastletter!="") {
trans.mat[rownames(trans.mat)==lastletter,27]=
trans.mat[rownames(trans.mat)==lastletter,27]+1
}
lastletter=""
}
trans.prob.mat=sweep(trans.mat+1,1,rowSums(trans.mat+1),FUN="/")
I like to visualize my data to make sure everything looks correct. Below is a plot of the transition matrix. The blank space corresponds to non-letter character. A lot of insights can be garnered from this plot. The Q-U relationship pops out. T is the most likely letter to start a word. E is a popular letter to follow many others. Y is likely to end a word.
Created by Pretty R at inside-R.org
The desired solution will be the one that gives the highest likelihood. This is an NP-hard problem so the only way to find the solution is to try all 26! combinations of mappings, which is infeasible, and report the one with the highest likelihood.
With the MCMC approach you start with a random mapping of letters. Next you propose a new mapping by randomly switching 2 of the characters in the mapping. So if A mapped to G and L mapped to Z and you switched those two, A would map to Z and L would map to G. With this new mapping, you measure the likelihood and divide it by the likelihood of the previous mapping. If this ratio is greater than 1, then move to this new mapping. If the ratio is less than 1, meaning the new mapping is less likely, then move to this new mapping with a probability equal to the ratio. (Practically, this is done by drawing a random uniform number between 0 and 1 and moving to the proposed mapping if the uniform number is less than the ratio.) Repeat this process until you think you have found a solution.
To do this, I first wrote a few functions. One to decode the coded text based on the mapping. The other was to calculate the log likelihood of the decoded text.
decode <- function(mapping,coded) {
coded=toupper(coded)
decoded=coded
for (i in 1:nchar(coded)) {
if (substring(coded,i,i) %in% toupper(letters)) {
substring(decoded,i,i)=toupper(letters[mapping==substring(coded,i,i)])
}
}
decoded
}
log.prob <- function(mapping,decoded) {
logprob=0
lastletter=""
for (i in 1:nchar(decoded)) {
curletter=substring(decoded,i,i)
if (curletter %in% toupper(letters)) {
logprob=logprob+log(trans.prob.mat[rownames(trans.mat)==lastletter,
colnames(trans.mat)==curletter])
lastletter=curletter
} else {
if (lastletter!="") {
logprob=logprob+log(trans.prob.mat[rownames(trans.mat)==lastletter,27])
lastletter=""
}
}
}
if (lastletter!="") {
logprob=logprob+log(trans.prob.mat[rownames(trans.mat)==lastletter,27])
lastletter=""
}
logprob
}
To show how this works, I will use the same Shakespeare text that is used in the MCMC Revolution paper. I let it run until it tries out 2000 different mappings (not the same as 2000 iterations, because rejected proposals are not counted). Along the way I am keeping track of the most likely mapping visited, and that will be the final estimate. It should be noted that I am only considering the mapping of letters and it is assumed that the special characters are known. For example spaces and periods are assumed to be the same.
correctTxt="ENTER HAMLET HAM TO BE OR NOT TO BE THAT IS THE QUESTION WHETHER TIS NOBLER IN THE MIND TO SUFFER THE SLINGS AND ARROWS OF OUTRAGEOUS FORTUNE OR TO TAKE ARMS AGAINST A SEA OF TROUBLES AND BY OPPOSING END"
coded=decode(sample(toupper(letters)),correctTxt) # randomly scramble the text
mapping=sample(toupper(letters)) # initialize a random mapping
i=1
iters=2000
cur.decode=decode(mapping,coded)
cur.loglike=log.prob(mapping,cur.decode)
max.loglike=cur.loglike
max.decode=cur.decode
while (i<=iters) {
proposal=sample(1:26,2) # select 2 letters to switch
prop.mapping=mapping
prop.mapping[proposal[1]]=mapping[proposal[2]]
prop.mapping[proposal[2]]=mapping[proposal[1]]
prop.decode=decode(prop.mapping,coded)
prop.loglike=log.prob(prop.mapping,prop.decode)
if (runif(1)<exp(prop.loglike-cur.loglike)) {
mapping=prop.mapping
cur.decode=prop.decode
cur.loglike=prop.loglike
if (cur.loglike>max.loglike) {
max.loglike=cur.loglike
max.decode=cur.decode
}
cat(i,cur.decode,"\n")
i=i+1
}
}
The output of this example is below. You can see that it comes close but it doesn't quite find the correct mapping. I attribute this to the fact that the text I was trying to decode only had 203 characters. In the paper mentioned above, they decoded the whole play. They further say that their methods work just as well if you randomly sample a text snippet 2000 characters long. Obviously my example had well less than this. This is also a problem in trying to solve a cryptogram because those are even smaller than the Hamlet example I used. So unfortunately this simple method cannot be used for that. (Note that I ran the MCMC chain a several times, using different random starting points, until it came reasonably close to the solution. This is something that the authors also suggested doing.)
I want to also note that I originally used Alice and Wonderland as the reference text. It had more trouble decoding since this book is much smaller than War and Peace, and therefore the transition probabilities were not as good.
The MCMC method is a greedy approach in that you are moving to any mapping that increases the likelihood. Greedy methods are not optimal in general because they can get stuck at local modes, especially in high dimensional problems. MCMC avoids this be moving to less likely mappings with some probability, which ensures that it will find the correct solution with enough time.
This work is cool!
I wrote my own substitution cipher decoder using the algorithm described in Stephen Connor's dissertation as the basis, but I occasionally glanced at your work as well.
My code doesn't work as awesomely as yours, and it is also much slower (possibly because I use 76 versus the 27 characters, reachChar versus readLine), and I use different functions.
But I cited your work and copied your idea for the melt matrix, which is ingenious.
Thanks so much!
Vivek
1- get the vector of words (using scan() for example).
2- For each word, use strsplit(word, NULL)[[1]] and iterate
over the characters to populate the matrix.
there are some old matlab code from the original consultancy work,
but I never tryed to replicate the example.
I got an error at:
ggplot(melt(trans.prob.mat),aes(Var2,Var1))+...
the melt() function uses X1 and X2:
> tmp <- melt(trans.prob.mat)
> head(tmp)
X1 X2 value
1 A A 3.893588e-05
2 B A 9.252956e-02
...
Cheers,
Pablo